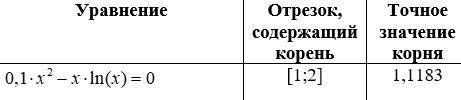
Составить программу (Python) нахождения корня уравнения с заданной точностью , не менее чем двумя-тремя методами. Если за заданное число шагов (по умолчанию взять 20-50) точность не будет достигнута, то вывести соответствующее сообщение и закончить вычисления, иначе вывести найденное значение корня, число шагов, за которое оно было найдено, и значение функции в корне. Также для каждого из методов необходимо вывести время вычислений, если время одного вычисления слишком маленькой (0 мс), то вычисление корня необходимо повторить несколько тысяч раз (миллионов) с одними и теми же начальными данными (первоначальными, которые ввел пользователь).
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.)[4][5]. Применение этого стандарта позволяет закодировать очень большое число символов из разных систем письменности: в документах, закодированных по стандарту Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, символы музыкальной нотной нотации, при этом становится ненужным переключение кодовых страниц[6].
Стандарт состоит из двух основных частей: универсального набора символов (англ. Universal character set, UCS) и семейства кодировок (англ. Unicode transformation format, UTF). Универсальный набор символов перечисляет допустимые по стандарту Юникод символы и присваивает каждому символу код в виде неотрицательного целого числа, записываемого обычно в шестнадцатеричной форме с префиксом U+, например, U+040F. Семейство кодировок определяет преобразования кодов символов для передачи в потоке или в файле.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII, и коды этих символов совпадают с их кодами в ASCII. Далее расположены области символов других систем письменности, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем[7]. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F (см. Кириллица в Юникоде)[8].
from random import randint
def task_26():
"""
26. дано число, введенное с клавиатуры.
определите сумму квадратов нечетных цифр в числе.
"""
def square():
number = int(input("number: "))
s = 0
for x in str(number):
if int(x) % 2 ! = 0:
s += int(x) ** 2
print("cума квадратов нечетных цифр в числе = {}".format(s))
square()
def task_27():
"""
27. найдите сумму чисел, вводимых с клавиатуры.
количество вводимых чисел заранее неизвестно.
окончание ввода, например, слово «стоп».
"""
def number_sum():
numbers_sum = 0
while true:
number = input("number: ")
if number == 'стоп' or number == 'стоп':
break
else:
numbers_sum += int(number)
print('suma {}'.format(numbers_sum))
number_sum()
def task_28():
"""
28. задана строка из стихотворения:
«мой дядя самых честных правил, когда не в шутку занемог,
он уважать себя заставил и лучше выдумать не мог»
удалите из строки все слова, начинающиеся на букву «м».
результат вывести на экран в виде строки.
подсказка: вспомните про модификацию списков.
"""
def word_deleted(line):
line_split = line.split()
for i in range(len(line_split) - 1): # 0,19
if line_split[i][0] == "м" or line_split[i][0] == "м":
del line_split[i]
return line_split
lines = "мой дядя самых честных правил, когда не в шутку занемог, " \
"он уважать себя заставил и лучше выдумать не мог"
print(word_deleted(lines))
def task_32():
"""
32. создайте матрицу (список из вложенных списков)
размера n x n (фиксируются в программе), заполненную случайными
целыми числами.
"""
def new_matrix(n):
matrix = [[randint(0, 100) for x in range(n)] for i in range(n)]
for x in matrix:
print(x)
new_matrix(10)
def task_45():
"""
45. напишите функцию, которая возвращает разность между наибольшим и
наименьшим значениями из списка целых случайных чисел.
"""
def difference():
number_random = [randint(0, 100) for i in range(50)]
print('разность между наибольшим и наименьшим значениями = {}'.format(
(max(number_random) - min(number_random))
))
difference()
def task_46():
"""
46. напишите программу, которая для целочисленного списка из 1000 случайных
элементов определяет, сколько отрицательных элементов располагается
между его максимальным и минимальным элементами.
"""
def num_random_count():
random_numbers = [randint(-500, 500) for i in range(1000)]
index_max = random_numbers.index(max(random_numbers))
index_min = random_numbers.index(min(random_numbers))
count = 0
list_range = random_numbers[index_min: index_max + 1]
for x in list_range:
if int(x) < 0:
count += 1
print("отрицательных элементов между максимальным и "
"минимальным элементами = {}".format(count))
num_random_count()
def task_50():
"""
50. дан список целых чисел. определить количество четных элементов и
количество элементов, оканчивающихся на цифру 5.
"""
def func(n):
test_list = [randint(0, 500) for i in range(n)]
count_num = 0
count_five = 0
for x in test_list:
if x % 2 == 0:
count_num += 1
if x % 10 == 5:
count_five += 1
print("количество четных элементов {}".format(count_num))
print("количество элементов, оканчивающихся на цифру 5. {}".format(
count_five))
func(50)
def task_51():
"""
51. задан список из целых чисел. определить процентное содержание
элементов, превышающих среднеарифметическое всех элементов списка
"""
def func(n):
test_list = [randint(0, 100) for i in range(n)]
average = sum(test_list) / len(test_list)
count = 0
for x in test_list:
if x > average:
count += 1
print("процентное содержание элементов, превышающих"
" среднеарифметическое всех элементов списка = {} %".format(
round((count / average) * 100,
func(100)
if __name__ == "__main__":
task_26()
task_27()
task_28()
task_32()
task_45()
task_46()
task_50()
task_51()
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.)[4][5]. Применение этого стандарта позволяет закодировать очень большое число символов из разных систем письменности: в документах, закодированных по стандарту Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, символы музыкальной нотной нотации, при этом становится ненужным переключение кодовых страниц[6].
Стандарт состоит из двух основных частей: универсального набора символов (англ. Universal character set, UCS) и семейства кодировок (англ. Unicode transformation format, UTF). Универсальный набор символов перечисляет допустимые по стандарту Юникод символы и присваивает каждому символу код в виде неотрицательного целого числа, записываемого обычно в шестнадцатеричной форме с префиксом U+, например, U+040F. Семейство кодировок определяет преобразования кодов символов для передачи в потоке или в файле.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII, и коды этих символов совпадают с их кодами в ASCII. Далее расположены области символов других систем письменности, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем[7]. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F (см. Кириллица в Юникоде)[8].
с инета