Структура данных – дек. Элементами дека являются натуральные числа. Удалите из дека
элементы, являющиеся простыми числами. Расположите оставшиеся элементы
в порядке убывания.
Обязательные: добавление элемента в один конец, добавление элемента в
другой конец, удаление элемента с одного и с другого конца. Дополнительные:
неразрушающее чтение элемента с любого конца, проверка заполнения дека, проверка пустоты дека.
Дан в прикрепленном изображении
Объяснение:
Для этого воспользуемся операциями целочисленного деления и получения остатка от деления. Целочисленное деление (//) - это деление с округлением вниз до целых. Это подходит нам по задаче. Если в одной упаковке находится 13 карандашей, в двух - 26, а нам нужно купить 24, нам придется взять только одну упаковку, чтобы не брать лишние. Остаток от деления (%) - это та разница, которую мы сбрасываем округлением.
Пусть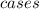 - количество упаковок, которые требуются для покупки k карандашей (получено в результате целочисленного деления на 13), а
- количество упаковок, которые требуются для покупки k карандашей (получено в результате целочисленного деления на 13), а 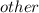 - количество карандашей, которые нужно докупить (получено в результате взятия остатка от деления на 13). Это количество будет строго меньше 13, так как если бы оно было бы больше, мы бы взяли вместо этого упаковку. Справедливо, что
- количество карандашей, которые нужно докупить (получено в результате взятия остатка от деления на 13). Это количество будет строго меньше 13, так как если бы оно было бы больше, мы бы взяли вместо этого упаковку. Справедливо, что
То есть вы знаете, что такое filter, что такое лямбда-выражения, для чего нужен префикс " * ", но при этом не знаете, как считывать какие либо данные с клавиатуры?)))
Если вам нужно считывать слова по одному, вы можете воспользоваться генератором списков:
words = [input() for _ in range(N)] #где N - произвольная длина вводимого списка
Если вы хотите ввести все слова, которые нужно обработать, разом в одну строку, используйте строковый метод .split(sep) и вводите слова разделяя каким либо уникальным символом (обычно это просто пробел)
words = input().split(' ')
Если у вас есть сомнения по поводу вводимого текста, или в задании обговорено, что вводимый текст может быть хоть статьёй из газеты, используйте модули string и re, что бы удалить из текста всякую шелуху и уже потом с ним работать
import re
import string
rawInput = input()
CleanText = re.sub(r' +', ' ', re.sub(rf'[{string.punctuation}]|\n', '', rawInput)) #Это удалит из введённого текста повторяющиеся пробелы, знаки препинания и символы переноса строки
words = CleanText.split(' ')