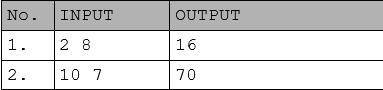
Вот описание задания: Напишите рекурсивную функцию int mul(int a, int b), которая вычисляет произведение двух целых чисел a и b. Единственная арифметическая операция, которую вы можете использовать в этой задаче, - это сложение +. Вот инпут и аутпут (фото):
Так, ну смотри... Я не стал запариваться и вручную записывать список с этими координатами... Это очень долго и муторно, я воспользовался модулями pickle и random, чтоб ускорить этот процесс... (____ - потом убери - это я табуляцию обозначил, чтоб было видно синтаксис нормально)
Я кусками объясню, потом выложу просто сами файлы...
Запись в файл идет бинарная, поэтому когда файл откроешь, там можешь увидеть страшные символы... Я подумал, что все равно в файле с координатами смотреть не на что. В любом случае я в самом конце использовал нормальную запись в файл тоже, можешь по аналогии и тут убрать модуль pickle. Но как по мне он удобнее.
Я сделал словарь, потому что изначально была идея обозвать каждую точку буквами А, В, С... и т.д., но это долго и муторно, поэтому когда вызовешь словарь, увидишь что там такой вид (ключ: 1; [x,y]). Тоже думаю вполне себе неплохо выглядит... Рандом тут просто для того, чтоб самому ничего не выдумывать, а быстро записать разные значения, не более... Ну и так же рандом тут определяет количество точек.
f = open('INPUT.TXT', 'rb')
xy = pickle.load(f)
Тут идет все тот же pickle, но мы уже присваиваем переменной xy значение из файла. Тут все просто.
for i in xy:
___arr1.append(xy[i])
Цикл, который координаты из словаря переносит в список. Мне так просто проще работать со списками. (Вообще, моя идея с НАЗВАНИЕ:КООРДИНАТЫ оказалось провальной, поэтому чтоб избежать двух лишних строчек, можешь в самом начале изменить словарь на список =D)
Тут происходит основной процесс программы. Цикл while работает до тех пор ПОКА длина списка arr1 больше 0. (сейчас к этому еще вернемся)
Цикл for перебирает значения списка arr1 (в котором у нас в виде списков координаты точек [x,y]) Удаляет первый элемент дабы избежать повторений и запускает второй цикл который уже без первой координаты... Получается что-то типа координата подается и со всеми остальными образует отрезок, потом вторая, третья и т.п...
И я думаю ты понял, зачем нам условие в цикле while len(arr1) > 0
Список закончился = он весь обработался...
Для следующей строки нам нужен модуль math, для упрощения жизни. тут просто формула, которая считает длины отрезков. Обычная формула из математики S = sqrt((x2 - x1)^2 + (y2 - y1)^2)
Ну думаю объяснять что за методы pow и sqrt - нет смысла...
За циклом к списку вызывается метод sort, который по порядку расставляет длины, которые мы насчитали. (т.к. у тебя в условии это требуется... бесполезное действие вообще как по мне =D)
f = open('OUTPUT.TXT', 'w')
f.write(str(len(arr2))+'\n')
for i in arr2:
___text = str(i) + '\n'
___f.write(text)
f.close()
А тут обычная запись уже в файл output. Ничего сложного. Первой строкой выводится количество отрезков, которое у нас получилось. На 26 точек, которые сгенерировались, у нас получилось 325 отрезков. Ну и из списка печатаются сами длины с отступом.
P.S. А, да... Чуть не забыл. У меня тут начало закомментировано как видишь... Тебе чтоб сгенерировать список, нужно сначала тройные кавычки убрать и желательно закомментировать оставшуюся часть кода... Когда у тебя будет уже файл input с значениями, можешь обратно поставить кавычки, чтоб у тебя вечно разные значения не генерировались :)
И я не смог загрузить файл с расширением .py, так что смотри на скрине, там синтаксис выделен, я думаю разберешься.
Компьютерные технологии всё глубже проникают во все сферы человеческой деятельности. Информатизация и компьютеризация требуют от людей новых навыков, новых знаний и нового мышления, призванных обеспечить адаптацию к условиям и реалиям компьютеризированного общества и обеспечить ему достойное место в этом обществе. Поэтому нельзя не согласиться с У. Мартином в том, что информатизация оказывает влияние на образ и качество жизни всех членов общества как на индивидуальном, так и на организационном уровне, на рабочем месте и в быту. Хорошо это или плохо, но она, пишет автор, представляет собой силу, которая не просто трансформирует жизнь целых сообществ, но перестройке самого «контекста отношений между людьми».
Так, ну смотри... Я не стал запариваться и вручную записывать список с этими координатами... Это очень долго и муторно, я воспользовался модулями pickle и random, чтоб ускорить этот процесс... (____ - потом убери - это я табуляцию обозначил, чтоб было видно синтаксис нормально)
import random, pickle, math
xy = dict()
for i in range(1, random.randrange(1,50)):
____xy[i] = [random.randrange(-104,104),random.randrange(-104,104)]
print(xy)
f = open('INPUT.TXT', 'wb')
pickle.dump(xy, f)
f.close()
Я кусками объясню, потом выложу просто сами файлы...
Запись в файл идет бинарная, поэтому когда файл откроешь, там можешь увидеть страшные символы... Я подумал, что все равно в файле с координатами смотреть не на что. В любом случае я в самом конце использовал нормальную запись в файл тоже, можешь по аналогии и тут убрать модуль pickle. Но как по мне он удобнее.
Я сделал словарь, потому что изначально была идея обозвать каждую точку буквами А, В, С... и т.д., но это долго и муторно, поэтому когда вызовешь словарь, увидишь что там такой вид (ключ: 1; [x,y]). Тоже думаю вполне себе неплохо выглядит... Рандом тут просто для того, чтоб самому ничего не выдумывать, а быстро записать разные значения, не более... Ну и так же рандом тут определяет количество точек.
f = open('INPUT.TXT', 'rb')
xy = pickle.load(f)
Тут идет все тот же pickle, но мы уже присваиваем переменной xy значение из файла. Тут все просто.
for i in xy:
___arr1.append(xy[i])
Цикл, который координаты из словаря переносит в список. Мне так просто проще работать со списками. (Вообще, моя идея с НАЗВАНИЕ:КООРДИНАТЫ оказалось провальной, поэтому чтоб избежать двух лишних строчек, можешь в самом начале изменить словарь на список =D)
while len(arr1) > 0:
___for i in arr1:
______arr1.pop(arr1.index(i))
______for z in arr1:
_________arr2.append(math.sqrt(math.pow(z[0]-i[0],2)+math.pow(z[1]-i[1],2)))
arr2.sort()
Тут происходит основной процесс программы. Цикл while работает до тех пор ПОКА длина списка arr1 больше 0. (сейчас к этому еще вернемся)
Цикл for перебирает значения списка arr1 (в котором у нас в виде списков координаты точек [x,y]) Удаляет первый элемент дабы избежать повторений и запускает второй цикл который уже без первой координаты... Получается что-то типа координата подается и со всеми остальными образует отрезок, потом вторая, третья и т.п...
И я думаю ты понял, зачем нам условие в цикле while len(arr1) > 0
Список закончился = он весь обработался...
Для следующей строки нам нужен модуль math, для упрощения жизни. тут просто формула, которая считает длины отрезков. Обычная формула из математики S = sqrt((x2 - x1)^2 + (y2 - y1)^2)
Ну думаю объяснять что за методы pow и sqrt - нет смысла...
За циклом к списку вызывается метод sort, который по порядку расставляет длины, которые мы насчитали. (т.к. у тебя в условии это требуется... бесполезное действие вообще как по мне =D)
f = open('OUTPUT.TXT', 'w')
f.write(str(len(arr2))+'\n')
for i in arr2:
___text = str(i) + '\n'
___f.write(text)
f.close()
А тут обычная запись уже в файл output. Ничего сложного. Первой строкой выводится количество отрезков, которое у нас получилось. На 26 точек, которые сгенерировались, у нас получилось 325 отрезков. Ну и из списка печатаются сами длины с отступом.
Весь код целиком:
import random, pickle, math
arr1 = []
arr2 = []
text = ''
'''xy = dict()
for i in range(1, random.randrange(1,50)):
___xy[i] = [random.randrange(-104,104),random.randrange(-104,104)]
print(xy)
f = open('INPUT.TXT', 'wb')
pickle.dump(xy, f)
f.close()
Данный код использовался для составления списка с случайным количеством координат и случайными его координатами.
'''
f = open('INPUT.TXT', 'rb')
xy = pickle.load(f)
for i in xy:
___arr1.append(xy[i])
while len(arr1) > 0:
___for i in arr1:
______arr1.pop(arr1.index(i))
______for z in arr1:
_________arr2.append(math.sqrt(math.pow(z[0]-i[0],2)+math.pow(z[1]-i[1],2)))
arr2.sort()
f = open('OUTPUT.TXT', 'w')
f.write(str(len(arr2))+'\n')
for i in arr2:
___text = str(i) + '\n'
___f.write(text)
f.close()
P.S. А, да... Чуть не забыл. У меня тут начало закомментировано как видишь... Тебе чтоб сгенерировать список, нужно сначала тройные кавычки убрать и желательно закомментировать оставшуюся часть кода... Когда у тебя будет уже файл input с значениями, можешь обратно поставить кавычки, чтоб у тебя вечно разные значения не генерировались :)
И я не смог загрузить файл с расширением .py, так что смотри на скрине, там синтаксис выделен, я думаю разберешься.
Компьютерные технологии всё глубже проникают во все сферы человеческой деятельности. Информатизация и компьютеризация требуют от людей новых навыков, новых знаний и нового мышления, призванных обеспечить адаптацию к условиям и реалиям компьютеризированного общества и обеспечить ему достойное место в этом обществе. Поэтому нельзя не согласиться с У. Мартином в том, что информатизация оказывает влияние на образ и качество жизни всех членов общества как на индивидуальном, так и на организационном уровне, на рабочем месте и в быту. Хорошо это или плохо, но она, пишет автор, представляет собой силу, которая не просто трансформирует жизнь целых сообществ, но перестройке самого «контекста отношений между людьми».
Объяснение: