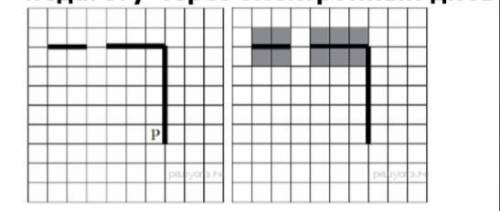
очень нужно (кумир) На бесконечном поле есть горизонтальная и вертикальная стены. Правый конец горизонтальной стены соединён с верхним концом вертикальной стены. Длины стен неизвестны. В горизонтальной стене есть ровно один проход, точное место прохода и его ширина неизвестны. Робот находится в клетке, расположенной рядом с вертикальной стеной слева от её нижнего конца. На рисунке указан один из возможных расположения стен и Робота (Робот обозначен буквой «Р»).
Напишите для Робота алгоритм, закрашивающий все клетки, расположенные непосредственно выше и ниже горизонтальной стены. Проход должен остаться незакрашенным. Робот должен закрасить только клетки, удовлетворяющие данному условию. Например, для приведённого выше рисунка Робот должен закрасить следующие клетки (см. рисунок).
При исполнении алгоритма Робот не должен разрушиться, выполнение алгоритма должно завершиться. Конечное расположение Робота может быть произвольным. Алгоритм должен решать задачу для любого допустимого расположения стен и любого расположения и размера проходов внутри стен.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.)[4][5]. Применение этого стандарта позволяет закодировать очень большое число символов из разных систем письменности: в документах, закодированных по стандарту Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, символы музыкальной нотной нотации, при этом становится ненужным переключение кодовых страниц[6].
Стандарт состоит из двух основных частей: универсального набора символов (англ. Universal character set, UCS) и семейства кодировок (англ. Unicode transformation format, UTF). Универсальный набор символов перечисляет допустимые по стандарту Юникод символы и присваивает каждому символу код в виде неотрицательного целого числа, записываемого обычно в шестнадцатеричной форме с префиксом U+, например, U+040F. Семейство кодировок определяет преобразования кодов символов для передачи в потоке или в файле.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII, и коды этих символов совпадают с их кодами в ASCII. Далее расположены области символов других систем письменности, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем[7]. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F (см. Кириллица в Юникоде)[8].
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.)[4][5]. Применение этого стандарта позволяет закодировать очень большое число символов из разных систем письменности: в документах, закодированных по стандарту Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, символы музыкальной нотной нотации, при этом становится ненужным переключение кодовых страниц[6].
Стандарт состоит из двух основных частей: универсального набора символов (англ. Universal character set, UCS) и семейства кодировок (англ. Unicode transformation format, UTF). Универсальный набор символов перечисляет допустимые по стандарту Юникод символы и присваивает каждому символу код в виде неотрицательного целого числа, записываемого обычно в шестнадцатеричной форме с префиксом U+, например, U+040F. Семейство кодировок определяет преобразования кодов символов для передачи в потоке или в файле.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII, и коды этих символов совпадают с их кодами в ASCII. Далее расположены области символов других систем письменности, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем[7]. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F (см. Кириллица в Юникоде)[8].
с инета
1.
1) 219[10] > 21[10]
2) 25[10] < 71[10]
Объяснение:
[10] - десятичная система
2.
ответ:
а) 211212 б) 201212
Объяснение:
Т.к. это двоичная система, то полный десяток это 2. То есть:
1 + 1 = 2
1 + 2 = 11
2 + 2 = 12
а) 101012
10112
211212
б) 100012
101112
201212
3.
ответ: 1011001_(2)
Объяснение:
Было бы неплохо, конечно, еще указать в каком из четырех обратных кодов это надо представить, но ладно. Разберем случай первого обратного кода:
1) отбросить знак минус (-38) => 38
2) перевести в двоичный код: 38_(10) = 100110_(2)
3) инвертировать все биты: 100110_(2) => 011001_(2)
4) приписать слева единицу, как знак отрицательного числа: 011001_(2) => 1011001_(2)